This initiative aims at providing researchers with a list of open source projects that use UML. The dataset includes links to more than 93 000 UML files (spread across more than 24 000 GitHub repositories).
How to cite this dataset?
If you use this dataset, please, cite it. You can do so by referring to the following publication (Please, note that the publication reports on the method applied to identify UML in GitHub. The reported numbers reflect around 10% of the Lindholmen Dataset.): The Quest for Open Source Projects that Use UML: Mining GitHub;
Hebig, R. & Ho-Quang, T. & Robles, G. & Fernandez, M.A. & Chaudron, M.R.V. (2016).
In proceedings, ACM/IEEE 19th International Conference on Model Driven Engineering Languages and Systems, pages 173-183, Saint-Malo, France, October 2-7, 2016.
Abstract
Context: While industrial use of UML was studied intensely, little is known about UML use in Free/Open Source Software (FOSS) projects. Goal: We aim at systematically mining GitHub projects to answer the question when models, if used, are created and updated throughout the whole project’s life-span. Method: We present a semi-automated approach to collect UML stored in images, .xmi, and .uml files and scanned ten percent of all GitHub projects (1.24 million). Our focus was on number and role of contributors that created/updated models and the time span during which this happened. Results: We identified and studied 21 316 UML diagrams within 3 295 projects. Conclusion: Creating/updating of UML happens most often during a very short phase at the project start. For 12% of the models duplicates were found, which are in average spread across 1.88 projects. Finally, we contribute a list of GitHub projects that include UML files.
Download a manuscript of the paper (pdf); Download the replication package; Download the slides of the presentation (from MODELS 2016, 5th October 2016, Saint-Malo, France)
Publications
A number of studies have been taken about Lindholmen dataset. If you are interested in the dataset, you might want to have a look into the following publications:- Practices and perceptions of UML use in open source projects;
Ho-Quang, T. & Hebig, R. & Robles, G. & Chaudron, M.R.V. & Fernandez, M.A. (2017).
In proceedings of the 39th International Conference on Software Engineering: Software Engineering in Practice Track, Pages 203-212, Buenos Aires, Argentina — May 20 - 28, 2017.
- An extensive dataset of UML models in GitHub;
Robles, G. & Ho-Quang, T. & Hebig, R. & Chaudron, M.R.V. & Fernandez, M.A. (2017).
In Proceedings of the 14th International Conference on Mining Software Repositories, Pages 519-522, Buenos Aires, Argentina — May 20 - 28, 2017
Dataset
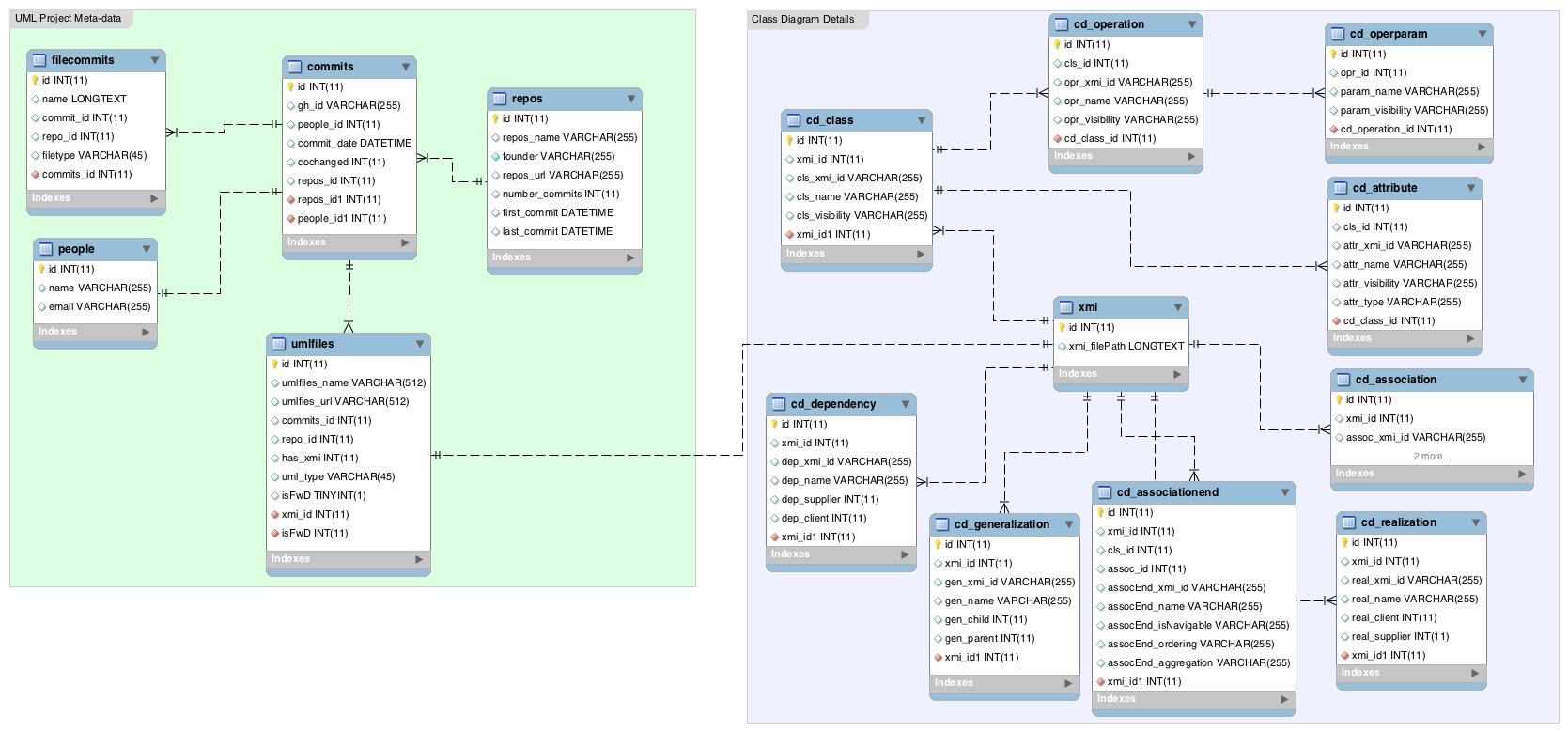
The dataset consists of 2 csv files. File Project_FileTypes includes the list of all projects with a summary per project, including the number of identified UML files and the file format (.xmi, .uml, .jpg, .jpeg, .svg, .bmp, .gif, or .png) of the UML files in that project. File UMLFiles_List includes the list of links to all identified UML files, sorted by project. In addition, we provide a database that contains meta-data of the projects (file Meta-data).
How to use this dataset?
- Use file Project_FileTypes to filter projects based on your needs with regards to the number of UMl files and file formats.
- To filter based on addition criteria use the project name (which is part of the link) and use the metadata directly available in GitHub (via the GitHub API) or the metadata summarized by the GHTorrent project.
- Directly access the projects using the link found in file Project_FileTypes if you want to study the UML files in the environment of their projects.
- Use file UMLFiles_List as a shortcut to access the UML files directly, if the projects are too big to search for the files manually or if you only want to study the models.
Disclaimer / Limitations
As every dataset, also this one has limitations that should be taken into account when using it.
- So far, we estimate that the data set includes around 30 000 class diagrams. This estimate bases on a semi-automated scan of the models. However, while we manually ensured that image files are UML, we did not assign a manual flag for the UML diagram type. We hope to resolve this limitation in future.
- While we put a huge effort into ensuring that the identified files are actual UML, it is still possible that the one or other mistake happened during this large scale effort. Please, make sure that the examples you pick conform to your needs.
- There are some general issues with data mined from repositories such as GitHub. One of those threats is the high amount of student or toy repositories within GitHub. Thus, you might want to filter the projects based on criteria such as size or the number of contributors. Kalliamvakou et al. provide a discussion about these threats. (E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian. The promises and perils of mining github. In Proceedings of the 11th Working Conference on Mining Software Repositories, MSR 2014, pages 92{101, New York, NY, USA, 2014. ACM.)
- This data set is by no means a complete list of projects with UML in GitHub. On the one hand, we only searched for a limited set of file formats that can contain UML. In addition, we only scanned non-forked GitHub projects. Thus, there is a high probability that UML files occur in other projects/repositories, too, e.g. if these are forks of UML repositories. Please do not use the dataset to draw premature conclusion about the frequency of UML within open source.
- GitHub is a dynamic environment. Projects that had been accessible during the time of this study might by now be private or deleted. Thus, some of the linked projects and models might not be accessible any more. We do not archive models within this website. For archived models please use other initiatives, such as Models-DB
Acknowledgement
We would appreciate Rodi Jolak, EL AHMAR Yosser, Bilal Karasneh and Dave Stikkolorum who helped us in identifying the UML images.Downloads (NEWS: Lindholmen version 2.0 is now available!!!)
Project_FileTypes
UMLFiles_List
Meta-data (1.3 GB compressed, 3.3 GB uncompressed)
Database_Schema
Description of the Data Schema
Change Logs between versions
{kind=link}
License

This dataset has been released under the Creative Commons Attribution-ShareAlike 4.0 (BY-SA) license.
This license lets others remix, tweak, and build upon your work even for commercial purposes, as long as they credit you and license their new creations under the identical terms. This license is often compared to "copyleft" free and open source software licenses. All new works based on yours will carry the same license, so any derivatives will also allow commercial use. This is the license used by Wikipedia, and is recommended for materials that would benefit from incorporating content from Wikipedia and similarly licensed projects.